
The 17 Questions That Tell You Whether You Are AI Fluent
A field test for operators, and the research behind every question. Answer all seventeen, score yourself, and download the worksheet at the end.


TL · DR (The 30-second version)
AI fluency is not knowing what AI can do. It is changing how your work actually gets done. Knowing the capability exists changes nothing on its own.
The research splits in two. Stanford finds 14 to 34 percent task-level gains. NBER finds 89 percent of executives see no enterprise boost. McKinsey finds only 6 percent capture real EBIT, and the one behavior that separates them is workflow redesign. The space between the two is the operator’s opportunity.
This is a 17-question field test, grouped under seven characteristics of the fluent operator. Each question is a binary, and the standard for yes is that you could show the artifact, the schedule, or the screen recording in the next ten minutes.
Score yourself 0 to 17. Four tiers: Curious, Practicing, Operating, Fluent. Most operators land at four or five and assume they are close. They are not.
The worksheet is at the end. Run it on yourself, then on the person who reports to you. The pattern of where you both stall is your build order.
If you have 30 seconds, read this. If you have 12 minutes, read the rest.
There is a quiet split within companies, and research has now measured both sides of the schism.
At the level of a single task, the gains are real and large. A Stanford study of 5,179 customer support agents found that access to a generative AI assistant raised output 14 percent on average and 34 percent for the least experienced workers. At the level of the whole enterprise, the same technology shows almost nothing. A National Bureau of Economic Research survey of 6,000 executives found 89 percent reporting no productivity gain from AI over three years. Goldman Sachs Research reached the same conclusion in 2026: no meaningful relationship between AI and productivity at the economy-wide level, alongside a median 30 percent gain in two narrow places, software engineering and customer service. The task data and the enterprise data are not the same data. The space between them is the operator’s opportunity.
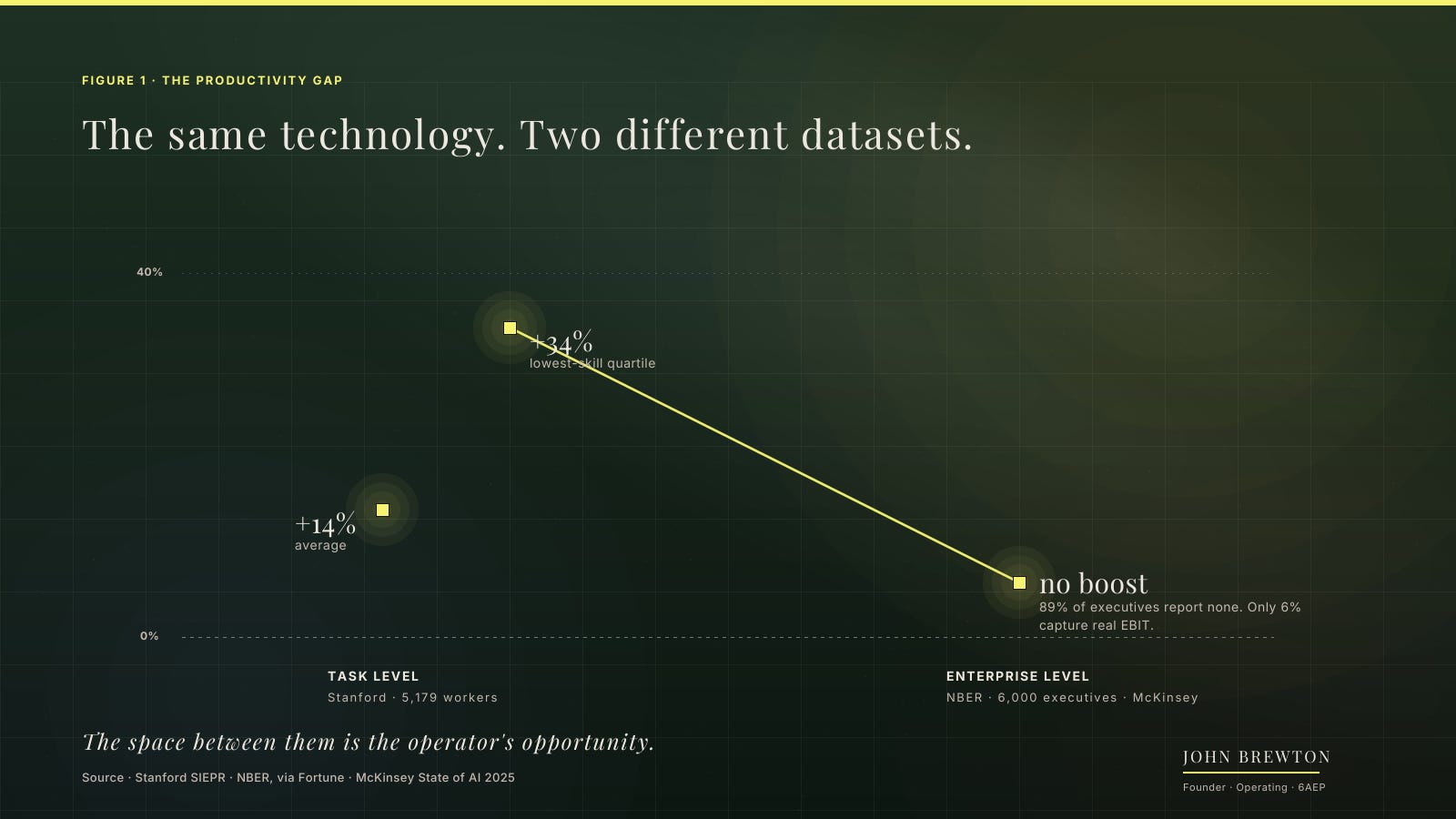
McKinsey put a number on who closes that space. In its late 2025 State of AI, 88 percent of organizations report using AI, and only 6 percent qualify as high performers capturing 5 percent or more of EBIT from it. The single strongest correlation with that impact is not model choice or budget. It is fundamental workflow redesign. High performers are nearly three times as likely as everyone else to say they have rebuilt how the work is done.
That finding is the whole argument of this piece. AI fluency is not knowing what AI can do. It is changing how your work actually gets done. Knowing the capability exists produces nothing. MIT found that 95 percent of enterprise AI pilots returned no measurable result, and the cause was not the model. It was the failure to redesign the work around it. Fluency lives in the work itself, not in the vocabulary around it.

So I built a test for it. Seventeen questions, grouped under seven characteristics of the fluent operator. Each one is grounded in the institutional research record, and each one has a single hard standard.

How to take this
Each question is a binary. Yes or no. No partials and no “kind of.”
The standard for a yes is strict. You could show the artifact, the schedule, or the screen recording in the next ten minutes. If your answer is a description of what is possible, the answer is no. If your answer is a piece of work that already runs differently, the answer is yes.
Count your yes answers as you go. There are four tiers at the bottom. Most operators assume they are most of the way there and land lower than they expect. That gap is the point of the exercise.
Section I · Do The Work
The job runs differently because AI is inside it.
1. Name one recurring deliverable you own that you now produce through an AI-assisted workflow you did not use twelve months ago. Could you show the before-and-after side by side?
A yes is a specific deliverable, a brief, a deck, a model, a memo, that is genuinely produced differently now. This is the load-bearing question. The Stanford gains showed up only for workers who changed how the task was done, not for workers who knew the tool existed.
2. Has your role, your weekly cadence, or your standard output changed in the last 90 days because AI is now inside the work, not adjacent to it?
A yes means something structural shifted, not that a few steps got faster. This is where the McKinsey finding bites hardest. Workflow redesign is the behavior that separates the 6 percent who capture real value from everyone else. The MIT pilots that failed bolted AI onto the old process. A faster version of a broken step is still a broken step.
Section II · Wired into the stack
No separate environment to switch into.
3. Is your AI connected to the apps you already live in, email, calendar, files, CRM, so you never copy and paste between a chat window and your real work?
A yes means the model reaches your systems of record directly. Andreessen Horowitz’s 2025 survey of 100 enterprise CIOs found enterprises expecting roughly 75 percent growth in model spend over the next year, and one CIO put it plainly: what I spent in 2023 I now spend in a week. The money is moving toward systems that act inside connected tools, not systems that chat.
4. Have you installed the six core connectors, email, calendar, CRM, Notion or Drive, Slack, and accounting, and can you name the last action each one took on your behalf?
A yes is four or more connectors live and in daily use. This is where the NBER number bites. Most of those 6,000 executives adopted tools and never connected them to the real work, and the productivity gain never arrived. Adoption without integration produces nothing.
Section III · Communications Hub
Comms and calendar run themselves.
5. Does a daily or weekly brief arrive on your screen without you asking for it, covering your inbox, your calendar, conflicts, and the highest-impact items of the day?
A yes is something useful that shows up unprompted. Goldman Sachs Research finds AI’s measured gains run near 30 percent but stay confined to narrow, localized use cases. The unprompted morning brief is exactly that kind of case. It is small, repeated, and it compounds.
6. Is your inbox triaged and your replies drafted before you open it most mornings, with scheduling that resolves without your direct intervention?
A yes means the rhythm of your communication runs with light touch. Thomson Reuters surveyed 2,275 professionals and found they expect AI to save them 5 hours a week, about 240 hours a year, worth roughly 19,000 dollars per person. Inbox triage is that routine work, and it is the first place most operators feel the week get lighter.
Section IV · Analysis
Analysis collapses to minutes.
7. Have you produced a board-ready or client-ready brief inside a single hour in the last 30 days, using a curated research workflow rather than an open chat?
A yes is a real artifact produced fast and clean. Stanford’s AI Index puts organizational adoption at 78 percent in 2024, with the clearest output gains in drafting and data preparation. A disciplined research brief is that gain, productionized into your week.
8. Have you constrained your research to a defined universe of Tier 1 publications, Tier 2 academic centers, and Tier 3 institutional shops, and can you name three sources you have excluded?
A yes means you build the research environment before you ask the question. Constraining the model to a defined source universe moves the signal-to-noise ratio from roughly 20 percent to roughly 90 percent in one move. The fluent operator never lets the model choose the sources. (This article is itself an example. Every link in it sits inside a curated source universe, and the appendix shows the architecture.)
9. In the last week, did you drop a CSV or pull live data, describe a question in plain English, and iterate to a publication-quality chart in under an hour?
A yes is the chart-building loop running without an analyst in the chain. In the Harvard and BCG study of 758 consultants, work inside AI’s reliable zone came back 40 percent higher in quality and 25 percent faster. The chart loop sits squarely inside that zone.
Section V · Agents
Headcount stops being the only way to add capacity.
10. Do you have at least one scheduled agent, written as a one-page spec with a defined job, defined access, and a defined report-back, that ran last week without you starting it?
A yes is one agent doing real work on a schedule. Harvard Business Review found that 91 percent of executives expect agentic AI to reshape work, and only 13 percent have shipped an agent. The agent count is the clearest marker of where you sit in that gap.
11. Do you have between four and seven agents carrying rhythm work, briefing, pipeline, follow-up, reconciliation, that used to sit on your desk?
A yes is a small team of agents holding the recurring load. Sequoia argues the next trillion-dollar company will not sell software but the work itself, delivered by agents, and draws a sharp line between a copilot that helps you work and an autopilot that returns the finished work. The operator who already runs a few autopilots is early to the thing the capital is chasing.
12. When an agent produces a bad outcome, do you know who owns the action, where the kill switch is, and how to scope its permissions tighter?
A yes means you run agents with discipline. HBR warns against treating an agent as an employee. Run each one with scoped permissions, observability, a kill switch, and a single named owner per action. The trust gap is the reason this matters. Only 6 percent of companies fully trust agents with core processes, and 48 percent name a lack of skills as the top barrier. Discipline is the skill that closes that gap.
Section VI · Standard
Speed and judgment improve together.
13. In the last 30 days, did you catch a confident, polished AI output that was wrong on a fact, a number, or a source, and correct it before it left your desk?
A yes means your judgment is active, not delegated. AI lifts some tasks and quietly degrades others of equal difficulty, with no signal telling you which. In the Harvard and BCG trial, work outside the model’s reliable frontier came back measurably worse. The fluent pattern keeps the human in the loop. Anthropic’s Economic Index found augmentation, where a person iterates with the model as a thinking partner, back above half of all use at 52 percent, ahead of hands-off automation. Your judgment is the filter, and a polished wrong answer is more dangerous than an obviously bad one.
14. Is the faster output you now produce holding up to scrutiny from a CEO, a board, a client, or an investor, with no cost to quality, sourcing, or defensibility?
A yes means speed did not come at the cost of standard. Robert Solow observed in the New York Times in 1987 that the computer age was visible everywhere except the productivity statistics. The lag closed when the output held up, not when it merely got faster. Fluency is faster output that survives scrutiny.
15. Have you cleared desk-work hours against a baseline you actually measured, not estimated, with 12 to 18 per week as the operator benchmark?
A yes requires a real measurement, not a feeling. A controlled trial by METR found that experienced developers were 19 percent slower with AI while believing they were 20 percent faster. Felt time saved is not measured time saved. If you have not measured, you cannot know which side of that gap you are on.
Section VII · Portability and leadership
Platform-agnostic. Teachable downward.
16. Could you rebuild your research workflow, your dashboards, and your agent team on a different platform inside a weekend if the field shifted tomorrow?
A yes means the capability lives in your habits, not in one vendor’s interface. Andreessen Horowitz found 37 percent of enterprises now run five or more models in production, up from 29 percent a year earlier, spreading spend on purpose to avoid lock-in. Fluency built on transferable habits survives the field moving under it.
17. Have you taught at least one other person to install and run one of your three builds on their own work, so fluency is a leadership capability and not a personal hack?
A yes is the capability installed in someone else. Mentions of generative-AI skills in job postings roughly quadrupled in a single year, from about 16,000 to 66,000. Fluency is now a hiring requirement, which makes the ability to teach it a leadership position rather than a personal trick.
Count Your Yes Answers

0 to 5 · Curious. You know the territory. You do not yet operate inside it. Start with the research architecture this weekend and connect the core six tools.
6 to 10 · Practicing. The builds are underway. The week has not yet been reshaped. The gap is usually the operator skills and the first scheduled agent. This is where most people stall and assume they have finished.
11 to 14 · Operating. The work runs differently. Time is being returned to judgment. Add agents until four to seven carry the rhythm work, then teach one other person.
15 to 17 · Fluent. The capability is portable, teachable, and inside the work. Install it across your team. Fluency is now a leadership position.
Most operators answer yes to four or five and assume they are close. The distance between five and seventeen is the entire competitive position of the job. The cost of staying at five for another quarter is the part nobody is pricing correctly yet.
Take the assessment
I have built these seventeen questions into a one-page worksheet. It is a fillable PDF with a yes and no box for every question, the four scoring tiers, and the build sequence to close your gaps. You can answer it on screen or print it and work through it with your team.
Download the AI Fluency Diagnostic worksheet (PDF)
Run it on yourself first. Then run it on the person who reports to you. The pattern of where you both stall tells you exactly where the next 30 days of work goes.

If you want to do the builds rather than just score them, I run a three-week sprint called Oper(AI)te that walks operators through all three, live, on their own work. Details are at unfazedfounder.com/operaite.
Frequently asked questions
What is AI fluency?
It is the ability to work differently because AI is in the loop. It is not knowledge of what AI can do. A fluent operator produces real deliverables through AI, runs research in minutes, and hands rhythm work to scheduled agents. MIT found 95 percent of enterprise pilots returned nothing measurable, because the work was never redesigned. Fluency is the redesign.
How is this different from being good at prompting?
Prompting is one input. Fluency is whether the work itself runs differently. You can write excellent prompts and still copy and paste between a chat window and your real job. This test measures the output and the system around it, not the prompt.
Do I need to be technical to score well?
No. The questions measure whether your work runs differently, not whether you can code. The operator’s skills are sequencing, source discipline, and judgment. The platform handles the technical layer.
What counts as a yes?
A yes is a piece of work you could show in the next ten minutes: the artifact, the schedule, or the screen recording. A description of what is possible is a no. There are no partials.
I scored lower than I expected. Is that normal?
Yes. Most operators answer yes to four or five and assume they are most of the way there. The distance from five to seventeen is the actual job. The questions you stall on are your build order.
Which gap should I close first?
Start with the research architecture and the core six connectors this weekend. Then stand up one scheduled agent. The four-tier read lists the sequence, and the worksheet repeats it.
Does the AI platform matter?
The capability spans Claude, ChatGPT, Gemini, and Perplexity and should move among them. Question 16 tests exactly that. Enterprises now run multiple models on purpose to avoid lock-in. Fluency that lives in one vendor’s interface is fragile.
How often should I retake it?
Every 90 days. That is the mark where the time savings stabilize, and a quarterly retake shows whether the builds held or drifted.
Is the worksheet free?
Yes. Download it below, run it on yourself, and work through it with your team.
Appendix · The research behind the assessment
Every claim in this article is sourced from a curated universe of Tier 1 publications, Tier 2 academic centers, and Tier 3 institutional research shops. The appendix organizes that record so you can pull the threads yourself.
A · The findings that anchor the assessment
1. Task-level productivity gains run 14 to 34 percent. Brynjolfsson, Li, and Raymond studied 5,179 support agents. Output rose 14 percent on average and 34 percent for the least experienced. [PEER-REVIEWED] Stanford SIEPR · Generative AI at Work
2. Enterprise-level surveys report no productivity boost. A survey of 6,000 executives across four countries found 89 percent reporting no productivity impact over three years. [EDITORIAL] NBER executive survey, via Fortune
3. Value concentrates in the 6 percent who redesign the work. McKinsey found 88 percent of organizations use AI, only 6 percent capture 5 percent or more of EBIT from it, and the strongest correlate of impact is fundamental workflow redesign. [INSTITUTIONAL] McKinsey · The State of AI, 2025
4. Adoption without redesign returns nothing. MIT’s NANDA initiative found 95 percent of enterprise AI pilots delivered no measurable P&L result. The root barrier was learning and workflow fit, not infrastructure or talent. [EDITORIAL] MIT NANDA · The GenAI Divide, via Fortune · full report PDF
5. The skill is in production, and the adoption gap is wide. Stanford’s AI Index puts organizational adoption at 78 percent in 2024, with gen-AI skill mentions in job postings rising from about 16,000 to 66,000 in a single year. [PEER-REVIEWED] Stanford HAI · 2025 AI Index Report
6. The capital is voting on agents. a16z’s survey of 100 enterprise CIOs found model spend growing roughly 75 percent year over year, with 37 percent of enterprises now running five or more models in production. [INSTITUTIONAL] Andreessen Horowitz · 100 Enterprise CIOs, 2025
B · Complicating evidence
Three findings push back on the simple version of the story. They belong in any honest read of the record.
AI can slow experienced people down. A randomized controlled trial found experienced developers were 19 percent slower with AI while believing they were 20 percent faster. [PEER-REVIEWED] METR · randomized controlled trial, July 2025
The frontier is jagged. AI improves some tasks 40 percent and degrades others of equal difficulty, inside the same workflow, with no signal which is which. [PEER-REVIEWED] Dell’Acqua, Mollick et al. · Navigating the Jagged Technological Frontier, Organization Science 2026 · SSRN working paper
Trust is the live constraint on agents. Only 6 percent of companies fully trust agents with core processes, 43 percent restrict them to routine work, and 48 percent cite a lack of skills as the top barrier. Run agents with scoped permissions, observability, kill switches, and a named owner. [EDITORIAL] HBR research, via Fortune · Why You Shouldn’t Treat AI Agents Like Employees, HBR 2026
C · The newest signals (2026)
Goldman sharpened the gap. Its 2026 update found no economy-wide productivity relationship, with the 30 percent gains localized to software engineering and customer service, even as AI capex climbed to a forecast 667 billion dollars. [INSTITUTIONAL] Goldman Sachs Research, via Fortune, March 2026 · Goldman · 7% global GDP forecast
Augmentation pulled back ahead of automation. Anthropic’s Economic Index found augmentation, where a person iterates with the model as a thinking partner, back above half of all use at 52 percent, ahead of hands-off automation. The judgment stays with the operator. [INSTITUTIONAL] Anthropic Economic Index, January 2026
Copilots are becoming autopilots. Sequoia argues the next trillion-dollar company will sell the finished work, not the tool, and notes that more tasks are now started by agents than by people. [INSTITUTIONAL] Sequoia Capital · Services: The New Software
The time math has a price. Thomson Reuters found professionals expect AI to save 5 hours a week, about 240 hours a year, worth roughly 19,000 dollars per person. [INSTITUTIONAL] Thomson Reuters · Future of Professionals, 2025
D · Historical parallel
The gap between task-level AI studies and enterprise-level surveys looks like the Solow paradox of the late 1980s. Robert Solow, writing in the New York Times in 1987, observed that you can see the computer age everywhere except in the productivity statistics. The lag stretched roughly a decade before the late-1990s acceleration. The operators who built the workflow during that lag captured the gains when the macro numbers finally turned.
E · Sources by tier
The elite-research architecture behind this assessment. Every source above sits in one of these three tiers.
Tier 1 · Elite publications
Harvard Business Review · Why You Shouldn’t Treat AI Agents Like Employees
[EDITORIAL]Harvard Business School Working Knowledge · Leadership in an Agentic AI World
[EDITORIAL]Fortune · NBER executive survey coverage
[EDITORIAL]Fortune · MIT GenAI Divide coverage
[EDITORIAL]Fortune · Goldman 2026 productivity coverage
[EDITORIAL]Fortune · HBR agent-trust coverage
[EDITORIAL]
Tier 2 · Academic research centers
Stanford SIEPR · Generative AI at Work
[PEER-REVIEWED]Stanford HAI · 2025 AI Index Report
[PEER-REVIEWED]Harvard and BCG · Navigating the Jagged Technological Frontier, Organization Science 2026
[PEER-REVIEWED]MIT NANDA · The GenAI Divide, State of AI in Business 2025
[PEER-REVIEWED]METR · Early-2025 AI and Developer Productivity
[PEER-REVIEWED]
Tier 3 · Institutional research
McKinsey · The State of AI, 2025
[INSTITUTIONAL]Goldman Sachs Research · AI and GDP
[INSTITUTIONAL]Andreessen Horowitz · 100 Enterprise CIOs, 2025
[INSTITUTIONAL]Sequoia Capital · Services: The New Software
[INSTITUTIONAL]Anthropic · Economic Index, January 2026
[INSTITUTIONAL]Thomson Reuters · Future of Professionals, 2025
[INSTITUTIONAL]
The source architecture above is the elite-research skill described in Question 8, applied to its own subject. Curate the universe, name the sources, exclude the rest.
John Brewton · Founder · Operating · 6AEP · Washington, DC
"my name is chris and I am Ai curious"
Insightful questions thanks John!